Snowflake Cloud Datawarehouse Architecture and Concepts
Snowflake is built for the cloud. Its architecture is what makes it unique. Snowflake is built on a patented, multi-cluster, shared data architecture created for the cloud to revolutionize data warehousing, data lakes, data analytics and a host of other use cases
In this tutorial, you will learn
- What is Snowflake Architecture ?
- Database Storage Layer
- Compute / Virtual Warehouse Layer
- Cloud Services Layer
- Advantages of Snowflake Architecture ?
- Simplicity
- Unlimited Scalable Compute
- Unlimited Capacity (Storage)
- Support for JSON and other SEMI-STRUCTURED data
- Data Sharing
- Maintenance
- How is Snowflake Architecture different from other Data Warehouse Platforms
- Snowflake Architecture Features
- Data Compression
- Data Encyption
- Columnar
- Zero Copy Cloning
What is Snowflake Architecture ?
Snowflake platform is comprised of storage, compute, and services layers that are logically integrated but scale infinitely and independent from one another
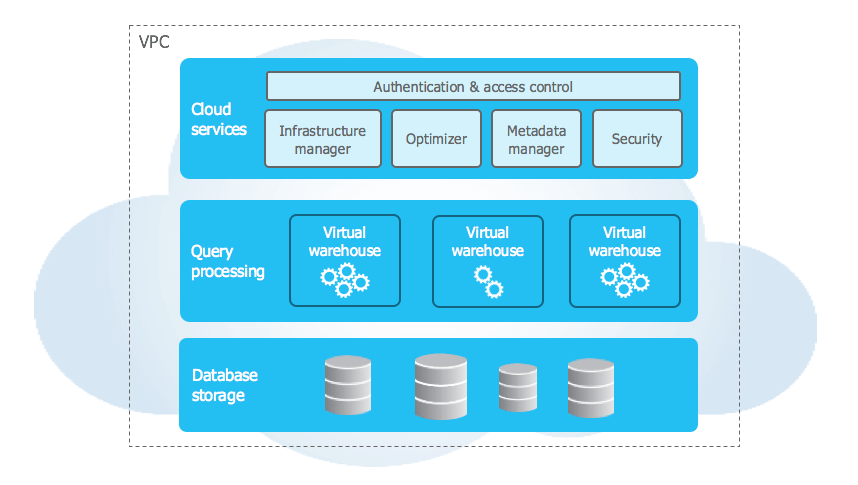
The Database Storage Layer
The Storage Layer is built on scalable cloud blob storage (uses the storage system of AWS, GCP or Azure), the storage layer holds all the diverse data, tables and query results for Snowflake. Maximum scalability, elasticity, and performance capacity for data warehousing and analytics are assured since the storage layer is engineered to scale completely independent of compute resources. As a result, Snowflake delivers unique capabilities such as the ability to process data loading or unloading, without impacting running queries and other workloads.
Under the covers of the storage layer, Snowflake utilizes micro-partitions to securely and efficiently store customer data. When loaded into Snowflake, data is automatically split into modest-sized micro-partitions, and metadata is extracted to enable efficient query processing. The micro-partitions are then columnar compressed and fully encrypted, using a secure key hierarchy.
Compute Layer
The compute layer is designed to process enormous quantities of data with maximum speed and efficiency. All data processing horsepower within Snowflake is performed by virtual warehouses, which are one or more clusters of compute resources. When performing a query, virtual warehouses retrieve the minimum data required from the storage layer to satisfy queries. As data is retrieved, it’s cached locally with computing resources, along with the caching of query results, to improve the performance of future queries
In addition, and unique to Snowflake, multiple virtual warehouses can simultaneously operate on the same data while fully enforcing global system-wide transactional integrity with full ACID compliance. Read operations (SELECT) always see a consistent view of data, and write operations never block readers. Transactional integrity across virtual warehouses is achieved by maintaining all transaction states within the services layer metadata.
Cloud Services Layer
The services layer is the brain. The services layer for Snowflake authenticates user sessions, provides management, enforces security functions, performs query compilation and optimization, and coordinates all transactions. The services layer is constructed of stateless compute resources, running across multiple availability zones and utilizing a highly available, distributed metadata store for global state management
The services layer also provides all security and encryption key management, and enables all Snowflake SQL DML and DDL functions. Queries are compiled within the services layer and metadata is used to determine the micro-partition columns that need to be scanned. Metadata processing is powered by a separate sub-system that’s also integrated with all of Snowflake
Advantages of Snowflake Architecture ?
Snowflake's unique architecture brings its own cutting edge advantages
Simplicity
Snowflake is so simple and intuitive. If you already know SQL, there is a very tiny learning curve. And there's nothing much changed from the developer's perspective. It supports ANSI SQL Standards and most of your existing reports should work fine without any issue
Unlimited Scalable Compute
In Snowflake, The Virtual warehouses come in T-shirt sizes, you can choose an XS / Small / Medium / XL / 2XL ...4XL. And you can enable autoscaling to scale proportionately to your load. And you only pay for the active usage, when you no more need them you can suspend them
Unlimited Capacity (Storage)
Unlike traditional databases, you don't have to allocate space to the databases, you simply create a database and tables and start loading data. The capacity will not run out. They never even ask me how much capacity I need. And actually, I don’t even care, since capacity is inexpensive. All too inexpensive
Support for JSON and other SEMI-STRUCTURED data
Snowflake’s architecture allows quick consolidation of all your diverse data onto one platform. Making this possible is their VARIANT data type. Snowflake loads semi-structured data as a VARIANT data type, enabling you to quickly query JSON in a fully relational manner
Data Sharing
You can also share data across your organization and outside your company to include your ecosystem of business partners and any external data consumers. You can accomplish this with granular, secure access and secure views of your data with no data movement involved
Maintenance
This is my favorite part. There are no PRIMARY KEYS, INDEXES, COLLECT STATS or other table tuning required in Snowflake. You simply create a table and start loading data. And for better, you don't need the infrastructure team and the DBA's to maintain it
How is Snowflake Architecture different from other Data Warehouse Platforms ?
Snowflake’s data warehouse is a true SaaS offering. More specifically:
There is no hardware (virtual or physical) for you to select, install, configure, or manage.
There is no software for you to install, configure, or manage.
Ongoing maintenance, management, and tuning is handled by Snowflake.
Snowflake runs completely on cloud infrastructure. All components of Snowflake’s service (other than an optional command line client), run in a public cloud infrastructure
Snowflake uses virtual compute instances for its compute needs and a storage service for persistent storage of data. Snowflake cannot be run on private cloud infrastructures (on-premises or hosted)
Snowflake is not a packaged software offering that can be installed by a user. Snowflake manages all aspects of software installation and updates
Snowflake Architecture Features
Data Compression
Compression is enabled by default. And takes place automatically
Data Encyption
All the data is encrypted by default (Even Amazon/Snowflake itself can't read your data)
Columnar
Snowflake is Columnar by default, so it only cares about that 5 columns in your report even if your table has a zillion columns
Zero Copy Cloning
Your ETL / Testing teams need a clone of Production data for testing? No problem its just a command away (and it does that without even duplicating the data)