What is Supervised Machine Learning Algorithm
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output
Its easier to grasp the concepts using an example: Lets consider the classic example from Andrew-ag's course. We have a data set with the house sq.ft and the prices they sold for. We can use this data to create a 2d plot like the below diagram and train our model
When we get a new query, say for example your friend wants to sell a 750sq.ft house, you can plot it in the model and we can predict how much it would sell for (approx 150k $)
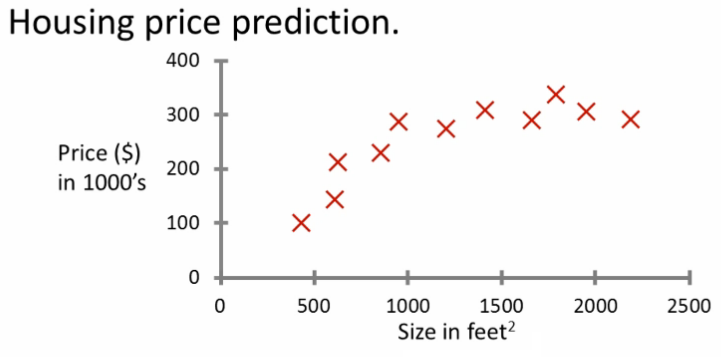
We call the above method as supervised learning. As the name implies, we train the model in this algorithm with a training data set with the correct answers, the algorithm learns the patterns from the training data. Learning stops when the algorithm achieves an acceptable level of performance. The majority of practical machine learning uses supervised learning
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories
Types of Supervised Learning:
Regression
- Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem
- Given a picture of a person, we have to predict their age on the basis of the given picture
Classification
Given a patient with a tumor, we have to predict whether the tumor is malignant or benign
- You are working on weather prediction, and you would like to predict whether or not it will be raining at 5pm tomorrow
- You are working on stock market prediction, Typically tens of millions of shares of Microsoft stock are traded (i.e., bought/sold) each day. You would like to predict the number of Microsoft shares that will be traded tomorrow
- Have a computer examine an audio clip of a piece of music, and classify whether or not there are vocals (i.e., a human voice singing) in that audio clip, or if it is a clip of only musical instruments (and no vocals)
- Given genetic (DNA) data from a person, predict the odds of him/her developing diabetes over the next 10 years
- Banks have to decide whether or not to give a loan to someone on the basis of his credit history