What is Overfitting in Machine Learning
When Machine Learning Models predict well on your training dataset, but performs poorly when it comes to examples outside your dataset, we call it "Overfitting"
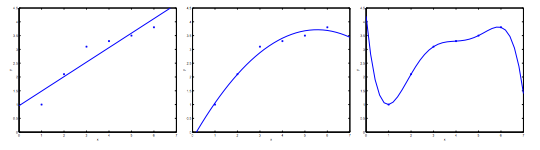
- The leftmost figure below shows the result of fitting a y = θ0 + θ1x to a dataset. We see that the data doesn’t really lie on straight line, and so the fit is not very good
- Instead, if we had added an extra feature x2 and fit y = θ0 + θ1x + θ2x2, then we obtain a slightly better fit to the data (See middle figure). Naively, it might seem that the more features we add, the better
- The rightmost figure is the result of fitting a 5th order polynomial y = ∑j=05θjxj We see that even though the fitted curve passes through the data perfectly, we would not expect this to be a very good predictor of, say, housing prices (y) for different living areas (x)
Without formally defining what these terms mean, we’ll say the figure on the left shows an instance of underfitting—in which the data clearly shows structure not captured by the model—and the figure on the right is an example of overfitting
What is Underfitting ?
Underfitting, or high bias, is when the form of our hypothesis function h maps poorly to the trend of the data. It is usually caused by a function that is too simple or uses too few features
What is Overfitting ?
overfitting, or high variance, is caused by a hypothesis function that fits the available data but does not generalize well to predict new data. It is usually caused by a complicated function that creates a lot of unnecessary curves and angles unrelated to the data
How to address the issue of Overfitting ?
There are two main options to address the issue of overfitting:
1) Reduce the number of features:
- Manually select which features to keep.
- Use a model selection algorithm (studied later in the course).
2) Regularization
- Keep all the features, but reduce the magnitude of parameters .
- Regularization works well when we have a lot of slightly useful features.