Top Google BigQuery Interview Questions & Answers
Quickly refresh these BigQuery concepts and win every interview that you appear for, with this list of Top BigQuery Data Warehouse Interview Questions that are frequently asked:
1. What is Unique about BigQuery Cloud Data Warehouse?
BigQuery is cloud native (built for the cloud).So, It takes advantage of all the good things about the cloud and brings exciting new features like,
- Auto scaling
- Unlimited Storage
- Time travel
- Military grade encryption and security
- Robust data protection features
And Bigquery comes with the below advantages:
- All the data is compressed by default
- All the data is encrypted by default
- Its Columnar, thereby making the column level analytical operations a lot faster
BigQuery also has a simple and transparent pricing, which makes it very easier even for smaller businesses to afford a cloud data warehouse
2. What are the different ways to access the BigQuery Cloud Datawarehouse ?
You can access the BigQuery Data Warehouse using
- Web User Interface
- ODBC Drivers
- JDBC Drivers
- BQ Command line Client
- Python Libraries
3. How does data compression works in BigQuery ?
All the data is compressed by default in BigQuery. BigQuery chooses the best compression algorithm and its not configurable by the end users. NOTE: Even though Google stores the data in compressed format internally, it charges the users for uncompressed size of data. (For both storage and compute)
4. What is BigQuery Caching ?
BigQuery caches the results of every query you ran and when a new query is submitted, it checks previously executed queries and if a matching query exists and the results are still cached, it serves the cached result set instead of fetching from the disk
5. Explain BigQuery Architecture ?
Bigquery is serverless, cloud native data warehouse. The storage and compute layers are decoupled and Bigquery automatically spins up the resources needed to execute the SQL. Bigquery compute is called as "slots", Bigquery automatically spins up the resources needed to execute the SQL
6. What is a BigQuery Columnar database and what are its benefits ?
Columnar databases organize data at Column level instead of the conventional row level. All Column level operations will be much faster and consume less resources when compared to a row level relational database
7. What are the data security features in Bigquery ?
Bigquery encrypts all customer data by default using End-to-end encryption (E2EE), using the latest security standards, at no additional cost. Bigquery provides best-in-class key management, which is entirely transparent to customers
- All the data is automatically encrypted by Bigquery using Google-managed keys or customer managed keys
- You can also setup VPC Service perimeters from where you could access the data
- All communication and data transfer between clients and the server protected through TLS
- You can Choose the geographical location where your data is stored, based on your cloud region
8. What is Snapshot decorator / Time Travel in BigQuery ?
The Snapshot decorator lets you access data as of any time in the past. For example, if you have a Employee table and if you delete the table accidentally you can use time travel and go back 5 minutes and retrieve the data back
9. What is the Time Travel duration in BigQuery ?
You can do time travel up to 7 days in the past. You can use undrop command to restore accidentally deleted tables for up to 2 days in the past
10. What is the PARTITION BY in BigQuery Table ?
"Partition by" as the name specifies, splits the table into multiple partitions. You can specify only one column as part of the PARTITION by clause. Its recommended to use the columns that are most likely to be used as part of the filter conditions as the partition key. Partition key helps with data pruning, reducing the amount of data scanned by the queries thereby reducing the overall cost. As of this writing, Bigquery only supports DATE, Timestamp and Numeric columns to be used as a Partition by column
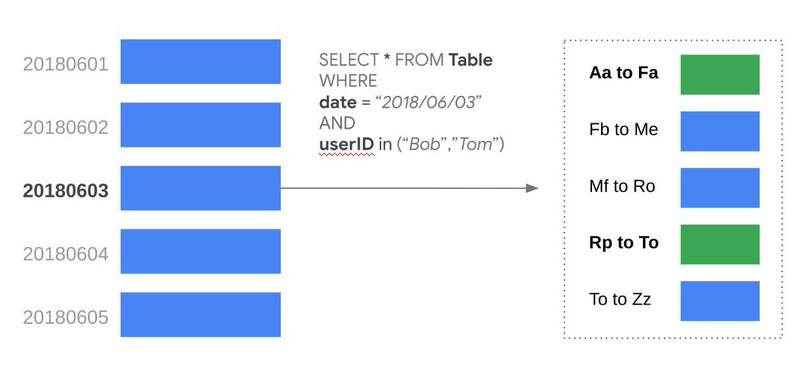
11. What is CLUSTER BY clause in BigQuery Table ?
Within a partition, Bigquery uses the cluster keys to sort the data. You can specify up to four columns as part of the cluster by clause. It is recommended to use the columns most likely used in the filter conditions as part of the cluster by clause
12. What is the difference between BigQuery and Snowflake
| Bigquery | Snowflake |
| Server less | Managed Servers |
| Data ingestion is free | Data ingestion requires virtual warehouse |
| Compressed Storage - you pay for uncompressed size though | Compressed storage |
| Pay for the amount of data scanned. (Currently, 5$ per 1TB of data scanned) | Pay for the virtual warehouse hours taken to execute the SQL |
| E2E encryption | E2E encryption |
| SQL based Machine learning - BQML | NA |
Post Comment