Google BigQuery Architecture and Concepts
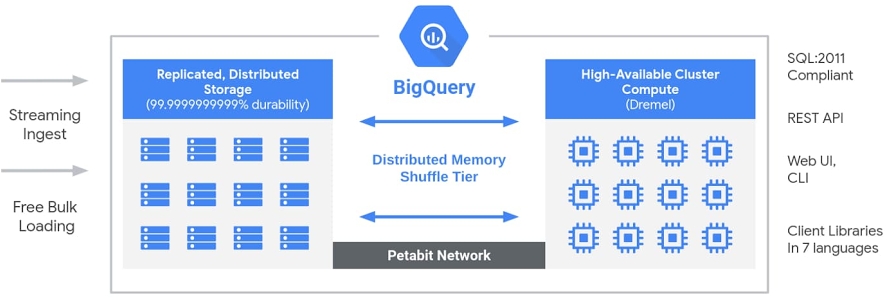
Google Bigquery has a unique Cloud Native architecture that allows for fast queries at petabyte scale using the distributed processing power of Google’s infrastructure.
Bigquery Architecture
As you see in the above picture,
- Storage and compute Layers are separated (decoupled) which allows them to scale independently on demand
- The Storage and compute layers are connected using a high speed network
- When a user submits a query, BigQuery will spin-up the compute on demand and then read the data from the distributed storage and fulfill the query.
- The decoupling of the storage and compute layers allows the compute layer to scale infinitely and support more queries and users
- This model also works for small and medium businesses customers as well
- Bigquery doesn't use the standard GCS buckets to store the data. It uses Colossus which is Google's proprietary storage system
Now that we know the high level architecture, lets take a deep dive into the internals of the Bigquery Engine
Bigquery Internal Architecture
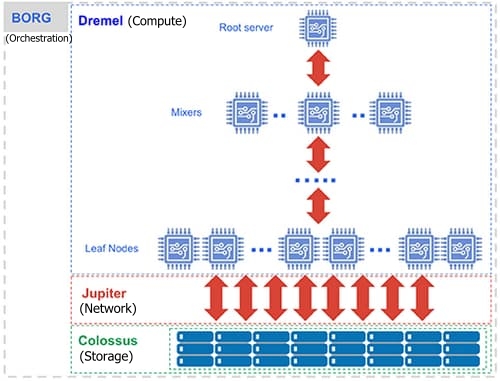
Internally Bigquery uses four components to fulfill and serve your query results:
Dremel (Compute Layer):
- Dremel parses SQL queries into execution trees. The leaves of the tree are called slots and do the actual work of reading data from storage and any necessary computation. The branches of the tree are ‘mixers’, which perform the aggregation
- Dremel dynamically allocates slots to queries, maintaining fairness for concurrent queries from multiple users
Colossus (Storage Layer)
- All the data is compressed and stored in columnar storage format in Colossus
- Colossus handles replication, recovery (when disks crash) and distributed management (so there is no single point of failure). Colossus enables users to scale to dozens of petabytes of data stored seamlessly
Jupiter Network
- Compute and storage talk to each other through the petabit Jupiter network. The Network is often referred to as the Shuffle
Borg (Orchestration engine)
- BORG is responsible for coordinating so all the parts of the engine can work seamlessly together, The mixers and slots are all run by Borg, which allocates hardware resources
Advantages of Bigquery Architecture
Bigquery with its serverless architecture, comes with the following benefits
- Simplicity - Bigquery is Simple and intuitive. Bigquery supports standard ANSI SQL. So most of your developers can get started in no time
- Maintenance - Bigquery is fully managed solution from Google, which means you don't need the overhead of Server admins, Database Admins etc. Moreover the database itself is mainenance free. (It doesnt have primary keys, indexes, statistics, vacuum etc)
- Unlimited Scalable Compute and Storage - Storage and Compute can grow according to your requirements. And you dont have to pay for any unused capacity
- Support for semi-structured data - Bigquery has rich support for semi-structed data as well. It works seamlessly with JSON formats, Arrays etc
- No Upfront Cost - Its very easy to start your cloud datawarehouse on Google. There are no upfront capital costs, zero maintenance and no capacity planning as your needs grow
How is BigQuery Architecture different from other Data Warehouse Platforms ?
- There is no hardware (virtual or physical) for you to select, install, configure, or manage.
- There is no software for you to install, configure, or manage.
- Ongoing maintenance, management, and tuning is handled by Bigquery with zero downtime
Post Comment