What is Dimensional Model in Data Warehouse?
What is a Dimensional Model ?
Dimensional modelling is used in Data Warehouse to organize data effectively and assist analytical operations on huge volumes of data. The concept of Dimensional Modelling was developed by Ralph Kimball and is comprised of "fact" and "dimension" tables
Data Warehouse uses denormalized tables (flat tables). (Whereas, database or OLTP systems use Normalized tables). So, to create this denormalized model effectively you will use a modelling technique called "Dimensional Modelling". A dimensional model is a data structure technique optimized for Data warehousing
In this tutorial, you will learn
- What is Dimensional Model?
- Elements of Dimensional Data Model
- Fact
- Dimension
- Attributes
- Steps in Dimensional Modelling
- Step 1: Understanding the Business Problem
- Step 2: Identify the grain
- Step 3: Identify the dimensions
- Step 4: Identify the Fact
- Step 5: Build Schema
- Dimensional Modelling Rules
- Benefits of dimensional modeling
Elements of Dimensional Data Model
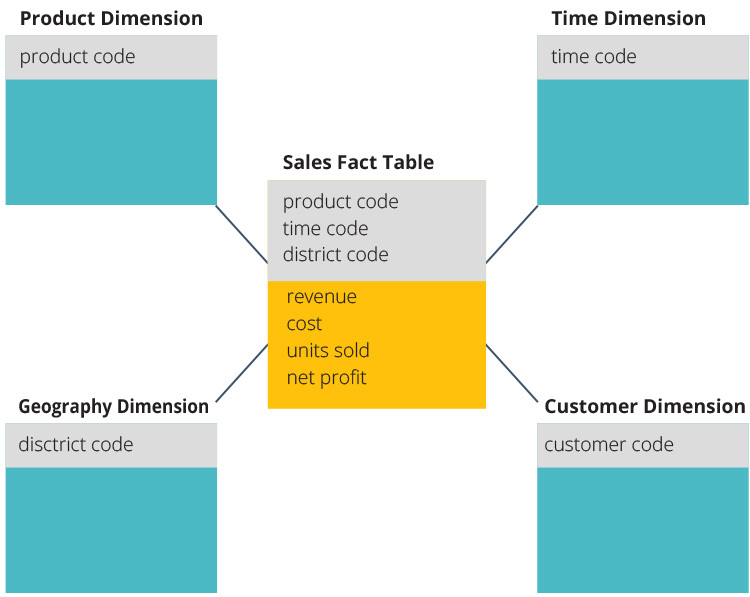
Fact
Fact table consists of the measurements, metrics or facts of a business process. It is located at the center of a star schema or a snowflake schema surrounded by dimension tables
Eg. Monthly sales volume, Average Customer Balance etc...
A Fact Table contains
- Measurements/facts
- Foreign key to dimension table
Dimension
A category of information. For example, the time dimension. In simple terms, they give who, what, where of a fact. In the Sales business process, for the fact quarterly sales number, dimensions would be
- Who - Customer Names
- Where - Location
- What - Product Name
- When - Time Dimension
- A dimension table contains dimensions of a fact
- They are joined to fact table via a foreign key
- Dimension tables are de-normalized tables
- The dimension can also contain one or more hierarchical relationships
Attributes
The Attributes are the various characteristics of the dimension.In the Location dimension, the attributes can be
- State
- Country
- Zipcode etc
Attributes are used to search, filter, or classify facts. Dimension Tables contain Attributes
Steps of Dimensional Modelling
A good dimensional model determines the success of your data warehouse implementation
Here are the steps in dimenstional data modelling- Understanding the Business Problem
- Identify Grain (level of detail)
- Identify Dimensions
- Identify Facts
- Build Star
Step 1: Understanding the Business Problem
Identifying the actual business process a datawarehouse should cover. This could be Marketing, Sales, HR, etc. as per the data analysis needs of the organization. It is the most important step of the Data Modelling process, and a failure here would have cascading and irreparable defects
Step 2: Identify the grain
The Grain describes the level of detail for the business problem/solution. It is the process of identifying the lowest level of information for any table in your data warehouse. If a table contains sales data for every day, then it should be daily granularity. If a table contains total sales data for each month, then it has monthly granularity. During this stage, you answer questions like
- Do we need to store all the available products or just a few types of products?
- Do we store the product sale information on a monthly, weekly, daily or hourly basis? This decision depends on the nature of reports requested by executives
- How do the above two choices affect the database size?
Step 3: Identify the dimensions
Dimensions are nouns like date, store, inventory, etc. These dimensions are where all the data should be stored. For example, the date dimension may contain data like a year, month and weekday
Example of Dimensions:The CEO at an MNC wants to find the sales for specific products in different locations on a daily basis
Dimensions: Product, Location and Time Attributes: For Product: Product key (Foreign Key), Name, Type, Specifications Hierarchies: For Location: Country, State, City, Street Address, Name
Step 4: Identify the Fact
This step is co-associated with the business users of the system because this is where they get access to data stored in the data warehouse. Most of the fact table rows are numerical values like price or cost per unit, etc.
Example of Facts:The CEO at an MNC wants to find the sales for specific products in different locations on a daily basis
The fact here is Sum of Sales by product by location by time
Step 5: Build Schema
The Database schema is designed and finalized in this step. There are two popular schemas
Star SchemaThe star schema architecture is easy to design. It is called a star schema because diagram resembles a star, with points radiating from a center. The center of the star consists of the fact table, and the points of the star is dimension tables
The fact tables in a star schema which is third normal form whereas dimensional tables are de-normalized Snowflake SchemaThe snowflake schema is an extension of the star schema. In a snowflake schema, each dimension are normalized and connected to more dimension tables
Dimensional Modelling Rules
- Load atomic data into dimension tables
- Design dimensional models around business processes
- Ensure that every fact table has an associated dimension table
- Ensure that all facts in a single fact table are at the same grain or level of detail
- Need to ensure that dimension tables use a surrogate key
Benefits of dimensional modeling
- Bring together data from many different sources and create a single, consistent user view
- Support the ad hoc queries that arise from real business questions
- Maximize flexibility and scalability
- Optimize the end-user experience