Data Warehouse Architecture
The Sourcing Layer
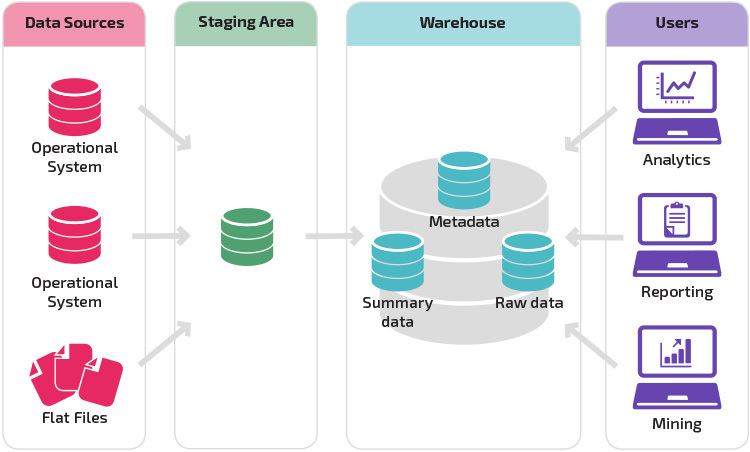
The raw files that are received from various sources are stored in the sourcing layer. Having one common area makes it easier for subsequent data processing / integration. Often we see NAS or Hadoop based platforms being used for the sourcing layer. For Cloud datawarehouses this would be the cloud storage buckets (usually GCS / S3 buckets / BLOB Storage)
Modern datawarehouse platforms support realtime straming ingestion. The sourcing layer applies only for batch loads. The Streaming inserts go directly in to the warehouse
Staging Area
The data is from sourcing layer is fetched and goes through the ETL process (Extract-Transform-Load), where its scrubbed, cleansed, standardised and in most cases de-normalized and then loaded to the stage tables. The CDC (Change data capture) happens during Stage to Warehouse inserts
Warehouse (Target) Layer
This is where the transformed and cleansed data sit. Based on scope and functionality, 3 types of entities can be found here: data warehouse, data mart, and operational data store (ODS). In any given system, you may have just one of the three, two of the three, or all three types
Semantic (Data Logic) Layer
This is where business rules are stored. Business rules stored here do not affect the underlying data transformation rules, but do affect what the report looks like
Data warehouse Architecture Best Practices
Here are some of the best practices while designing a data warehouse
- Use a data model which is optimized for information retrieval which can be the dimensional mode, denormalized or hybrid approach
- Design a MetaData architecture which allows sharing of metadata between components of Data Warehouse
- Need to assure that Data is processed quickly and accurately. At the same time, you should take an approach which consolidates data into a single version of the truth
- Carefully design the data acquisition and cleansing process for Data warehouse
- Consider implementing an ODS model when information retrieval need is near the bottom of the data abstraction pyramid or when there are multiple operational sources required to be accessed
- One should make sure that the data model is integrated and not just consolidated. In that case, you should consider 3NF data model. It is also ideal for acquiring ETL and Data cleansing tools