Guide to Snowflake Micro-partitioning and how it affects query performance

Snowflake is a cloud-native data warehouse solution. It uses Amazon S3 buckets or Azure blobs to actually store your table data in multiple smaller data files (also called as micro-partitions)
What are micro-partitions?
As you insert data into the snowflake table, the data is automatically divided into micro-partitions, in the same order as they arrive from the source. Each micro-partition contains between 50 MB and 500 MB of uncompressed data (note that the actual size in Snowflake is smaller because data is always stored compressed). Groups of rows in tables are mapped into individual micro-partitions, organized in a columnar fashion. So the very large tables can be comprised of millions, or even hundreds of millions, of micro-partitions
In the below example, we are loading daily transaction data, snowflake partitions them in the same order as the data arrives. NOTE: For simplicity sake, we have one micro-partition per day in the diagram. But in reality, you will have n number of micro-partitions a day
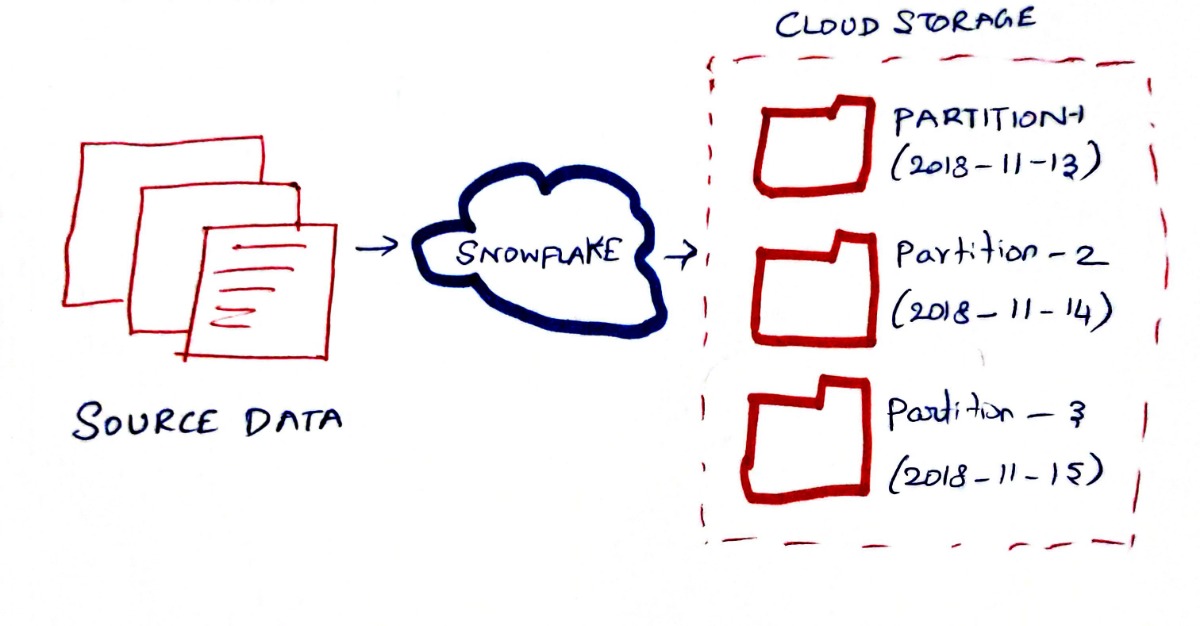
Snowflake also tracks and remembers the metadata about all rows stored in a micro-partition, including:
- The range of values for each of the columns in the micro-partition
- The number of distinct values.
- Additional properties used for both optimization and efficient query processing
How does micro-partitions help while retrieving the data?
For example, assume a large table containing one year of historical sales data with a date column. When the user queries a particular date, Snowflake knows exactly which micro-partitions has that data (Based on the micro-partition metadata). It will then only scan the portion of the micro-partitions that contain the data
What if my micro-partitions doesn't help while retrieving the data?
Often times, we have SQL Queries that do a full table scan. As the data is not sorted and stored in a logical fashion as required for retrieval. In that scenario, we can take control over the default snowflake micro-partitioning and define our own cluster-keys instead. Clustering is a huge topic on its own, so we will save it for another article.
How do you use/manipulate micro-partitions to speed up your reports? tell us in the comments
DataFreak
posted onEnjoy great content like this and a lot more !
Signup for a free account to write a post / comment / upvote posts. Its simple and takes less than 5 seconds
Post Comment