Google Bigquery Partitioning a table - Best practices
Bigquery uses partition keys to prune a table. It helps you reduce the amount of data scanned, which reduces the overall cost as well
Partitioning restrictions:
- In Bigquery, you can only partition by a date or timestamp column
- You can choose only one column for your partition. (However, you can have up to 4 columns as cluster keys)
- You cannot have more than 2000 partitions per table
Partitioning Benefits:
If a table is partitioned and when retrieving from the table if we specify the partition column in the where clause, its going to pull only that data and help you save on your querying costs as Bigquery charges for the amount of data scanned
How to choose a Partition Key:
Find out a date or timestamp column,
- That is most likely be used in the filter conditions
- The column will result in a decent sized partition. For smaller tables, Its efficient to have lesser number of partitions, so choose a column that will get you dense partitions, (eg. partitioning by year)
Here's an example:
Problem Statement: We are using a public dataset to benchmark BigQuery. We took the same table and partitioned it by day, but it's not clear we are getting many benefits. What's a good balance?
SELECT sum(score)
FROM `fh-bigquery.stackoverflow_archive.201906_posts_questions`
WHERE creation_date > "2019-01-01"
Takes 1 second, and processes 270.7MB.
Same, with partitions:
SELECT sum(score)
FROM `temp.questions_partitioned`
WHERE creation_date > "2019-01-01"
Takes 2 seconds and processes 14.3 MB.
So we see a benefit in MBs processed, but the query is slower.
What's a good strategy to decide when to partition?
Solution:
When partitioning a table, you need to consider having enough data for each partition. Think of each partition like being a different file - and opening 365 files might be slower than having a huge one.
In this case, the table used for the benchmark has 1.6 GB of data for 2019 (until June in this one). That's 1.6GB/180 = 9 MB of data for each daily partition.
- For such a low amount of data - arranging it in daily partitions won't bring much benefits. Consider partitioning the data by year instead
- Another alternative is not partitioning the table at all, and instead using clustering to sort the data by date. Then BigQuery can choose the ideal size of each block.
If you want to run your own benchmarks, do this:
CREATE TABLE `temp.questions_partitioned`
PARTITION BY DATE(creation_date)
AS
SELECT *
FROM `fh-bigquery.stackoverflow_archive.201906_posts_questions`
vs no partitions, just clustering by date:
CREATE TABLE `temp.questions_clustered`
PARTITION BY fake_date
CLUSTER BY creation_date
AS
SELECT *, DATE('2000-01-01') fake_date
FROM `fh-bigquery.stackoverflow_archive.201906_posts_questions`
Then my query over the clustered table would be:
SELECT sum(score)
FROM `temp.questions_clustered`
WHERE creation_date > "2019-01-01"
And it took 0.5 seconds, 17 MB processed.
| Type | Data Scanned | Slots time used | Query run time |
| Raw table | 270.7 MB | 10.683 sec | 1 sec |
| Partitioned Table | 14.3 MB | 7.308 sec | 2 sec |
| Clustered Table | 17 MB | 0.718 sec | 0.5 sec |
We have a winner! Clustering organized the daily data (which isn't much for this table) into more efficient blocks than strictly partitioning it by day
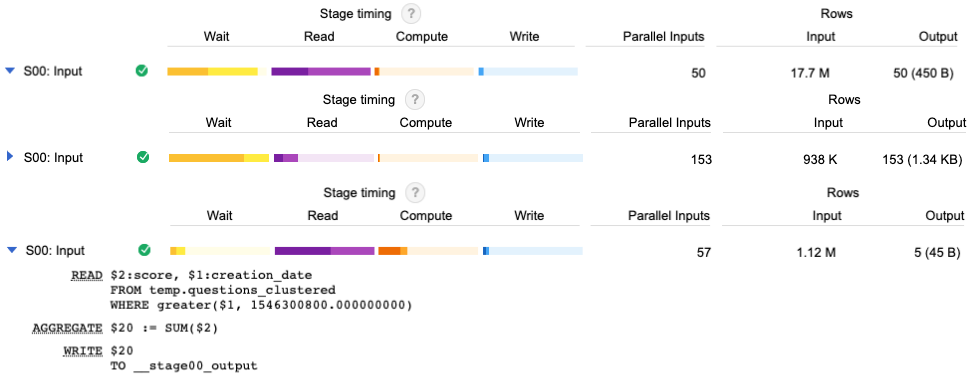
- As you can see, the query over raw table used a lot of slots (parallelism) to get the results in 1 second. In this case 50 workers processed the whole table with multiple years of data, reading 17.7M rows.
- The query over the partitioned table had to use a lot of slots - but this because each slot was assigned smallish daily partitions, a reading that used 153 parallel workers over 0.9M rows.
- The clustered query instead was able to use a very low amount of slots. Data was well organized to be read by 57 parallel workers, reading 1.12M rows

victor
posted onEnjoy great content like this and a lot more !
Signup for a free account to write a post / comment / upvote posts. Its simple and takes less than 5 seconds
Post Comment